
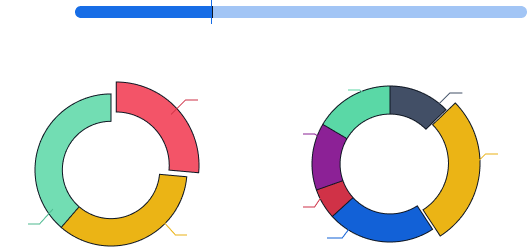
ディープラーニング技術に基づき、潜在的な感情や気持ちを分析するインテリジェント技術を提供し、顧客の本音を把握することで、より人間味のあるサービスを実現します。
感情認識の結果は、ポジティブ・ニュートラル・ネガティブの極性分類に対応可能です。
また、「嬉しい」「感謝」「不満」「怒り」「不安」「驚き」など、より細かい感情分類にも対応しています。

膨大なデータと音声・言語融合技術により、意味レベルで異なるテキスト間の類似度を計算し、0〜1のスコアとして出力。スコアが高いほど、テキストの類似度が高いことを示します。
さまざまな長さのテキストに対応した分類が可能で、ユーザーによるカテゴリのカスタマイズにも対応。ツリー構造などの階層型分類や、フラット型の分類にも対応しており、業界特化のニーズに柔軟に応えます。
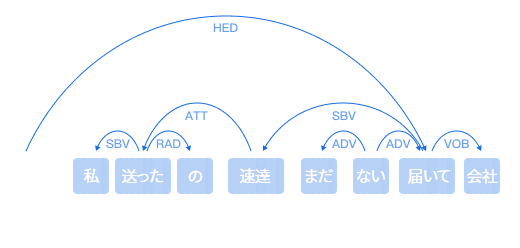
分かち書き、品詞タグ付け、固有表現認識などの自然言語処理の基礎技術を提供し、ユーザー定義辞書にも対応。さまざまな業種・シーンにおけるニーズに応えます。
